問題解説 Linux 筆記
解説
問題文
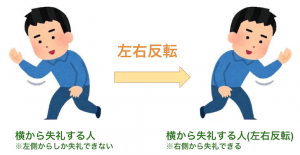
これはみんな大好きフリー素材を提供する、いやすとやの「横から失礼する人」です。
Aさんはこの画像を使って右側から失礼したかったのですが、元のままでは左側からしか失礼できません。
なんとかしたいAさんはこの画像を左右反転させることで右から失礼することに決めました。
<
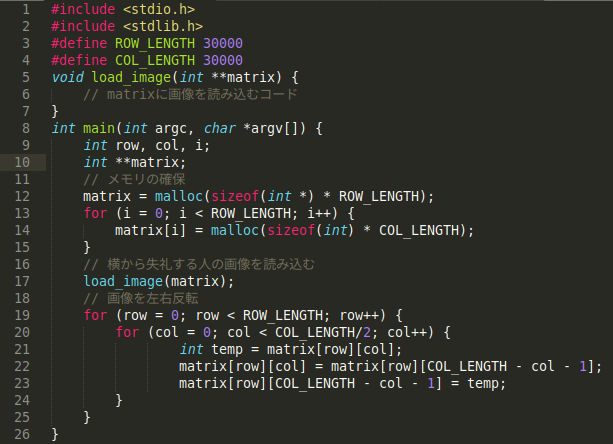
以下はC言語で書かれたAさんの左右反転するための擬似コードです。
Aさんのコード (左右反転)

flip_horizontal.c
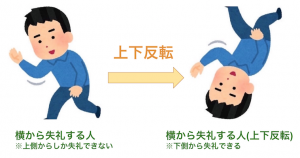
ところでその傍ら、Aさんの友人のBさんはこの画像を使って下側から失礼したかったのですが、元のままでは上側からしか失礼できないことに気づき困っていました。
なんとかしたいBさんはこの画像を上下反転させることで下から失礼することに決めました。
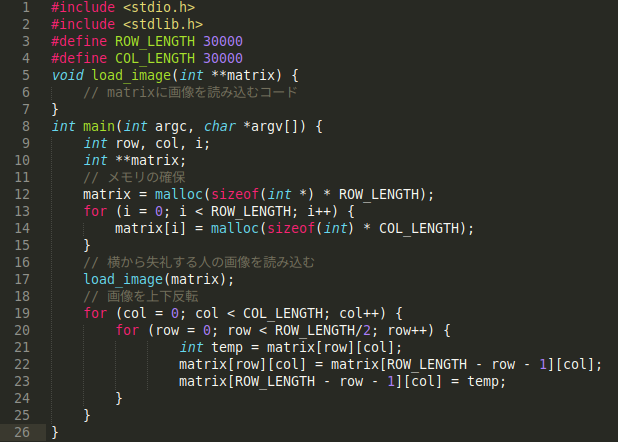
以下はC言語で書かれたBさんの上下反転するための擬似コードです。
Bさんのコード(上下反転)
flip_vertical.c
ところでこの横から失礼する人は縦横同じサイズの正方形の画像で二人とも同じもを使用した為、左右に反転させようと上下に反転させようと計算量は変わりません。
またAさんとBさんの実行環境は以下の通り全く同じものでした。OS: Ubuntu18.04 CPU: Intel(R) Xeon(R) CPU L5640 RAM: 48GBにもかかわらず、AさんとBさんのコードを実行した結果以下のように反転するのにかかる時間に大きな差が出てしまいました。
– Aさんのコードを実行: 約13秒
– Bさんのコードを実行: 約36秒
この差がなぜ出るのか困っているAさんとBさんのために、原因を記述し明らかにしてください。
また、Bさんはコードを速くするためにどうすればよかったのかも記述してください。
解説
解答のキーとしては
メモリアクセスの局所性 -> CPUのキャッシュメモリをうまく使用できたかどうか
がちゃんと記入できているかを特に重視して見ました。
一度参照した場所から近い場所が参照されると期待してキャッシュが行われる(メモリアクセスの局所性)ため、CPUのキャッシュメモリが生かされやすいかどうかが、AさんとBさんの違いにありました。
2次元配列の場合、mallocをみてもわかる通り、各rowに対して連続的にcolのメモリが確保されていることを踏まえるとメモリ上には例えばrow=0の時にcol = 0, 1, 2, …と連続的に確保され、次にrow=1の時col = 0, 1, 2,…という順番で確保されていることがわかります。
このことからAさんのコードでは内側のループにcolが来ていることから、できる限りメモリの連続したアドレスにアクセスできていることがわかります。
逆にBさんのコードでは内側のループがrowだったため、常に飛び飛びのアドレスにアクセスしていることがわかります。
結果Aさんの方がBさんよりもうまくキャッシュを活かせていたことがわかります。
以上を踏まえると、BさんのCPUメモリアクセスの順番を連続的にしてあげる = 内側と外側のforループの順番を変えてあげることでキャッシュをより活かせることができました。
具体的にはここの2重ループを逆にしてあげる必要がありました。
for (col = 0; col < COL_LENGTH; col++) {
for (row = 0; row < ROW_LENGTH/2; row++) {
???
}
}以下が逆にした2重ループです。
for (row = 0; row < ROW_LENGTH/2; row++) {
for (col = 0; col < COL_LENGTH; col++) {
???
}
}本来は上記のような解答を期待していたのですが、中には2次元配列の値を一つ一つ入れ替えずにrowの参照するcolの一次元配列をそのまま入れ替える、という解答もあり、確かにその方が簡単かつループ回数も減らせて計算量まで減らせるので、なるほどなぁと出題者も納得させられるものもありました。
つまり
row=0がcolの一次元配列その1を
row=1がcolの一次元配列その2を
row=2がcolの一次元配列その3を
...
row=nがcolの一次元配列そのn-1を
と参照しているため、row=0の配列とrow=n-1の配列の参照を、row=1の配列とrow=n-2の配列を...と入れ替えるだけで簡単に上下反転することができました。
for( row = 0 ; row < ROW_LENGTH/2; row++) {
int *temp = matrix[row];
matrix[row] = matrix[ROW_LENGTH - row - 1];
matrix[ROW_LENGTH - row - 1] = temp;
}これは素敵な解法ですが、これはインフラの問題というよりもプログラミングコンテストのような解法にはなってしまうので、出題者的にはできればメモリアドレスの局所性やCPUのメモリキャッシュの話をしてほしかったです。
最後に一つ目立った解答として、そもそもmallocのrowとcolの順番を入れ替えればいいのではないかという解答も複数見受けられましたが、その場合、確かにBさんのforループではメモリアドレスの局所性を考慮しうまくCPUのキャッシュは活かせるかもしれませんが、そのままではAさんと同じく左右反転を行ってしまっていることに注意して、image_loadの際にrowとcolを逆にする必要がある、という点も考慮する必要があります。